
Pandasを使うとcsvが簡単に読み込めて操作ができそうだったので、やってみました。
まず、pandasをインポートします。
import pandas as pd
今回は私がSpotifyで作っているプレイリストのデータを利用します。
df=pd.read_csv('09weeks2022.csv')
これだけで読み込めました。かなり楽ですね。
初心者としては、簡単で安心しました。
コラムのindexを表示するにはcolumnsを使います。
df.columns
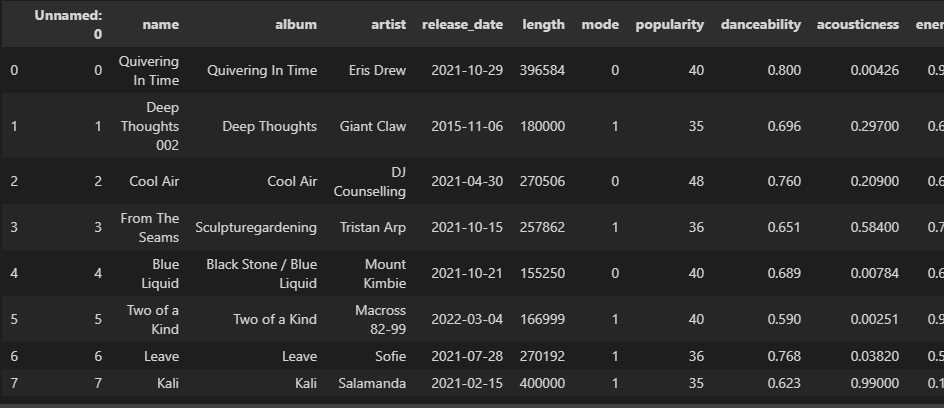
csvに必要ない列があったりします。
削除するには、上のcolumnsの列から不要な列を削除して、dfに上書きします。
今回の場合だと「Unnamed:0」を削除しました。
df=df[['name', 'album', 'artist', 'release_date', 'length', 'mode', 'popularity', 'danceability', 'acousticness', 'energy', 'instrumentalness', 'liveness', 'loudness', 'speechiness', 'tempo', 'time_signature', 'valence']]
削除できました。
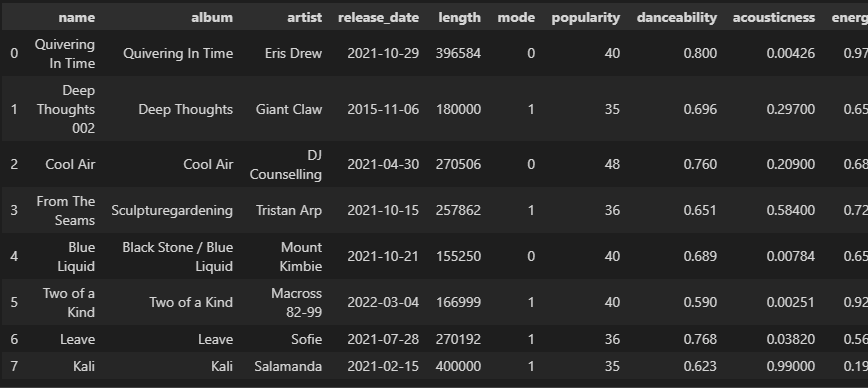
範囲選択する時は、ilocやlocを使います。
ilocを使ってみました。
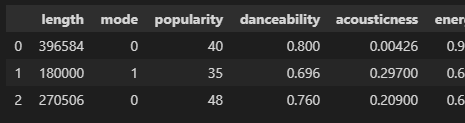
df.iloc[0:3,4:15]
0~3行、4~14列を抜き出しました。
次は、項目を指定して抜き出します。
df_select=df[['name','artist','popularity','danceability','tempo']]
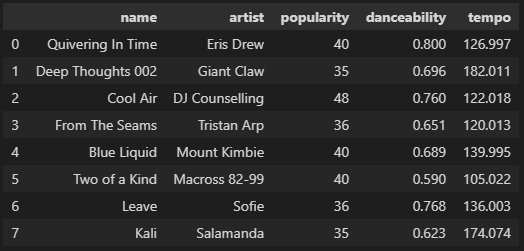
ソートする場合は、sort_valuesを使います。
df_select.sort_values('popularity')
その他
最初の3行を抜き出す場合
df.head(3)
最後の3行を抜き出す場合
df.tail(3)
列ごとのタイプを表示する場合
df.dtypes # name object # album object # artist object # release_date object # length int64
shapeで何行、何列かわかります。
df.shape
# (8, 17)
indexでstart、stop、stepがわかります。
df.index
# RangeIndex(start=0, stop=8, step=1)
